Model training parameters
Training a synthetic data generation model (or set of related models) requires several parameters to be provided:
The Max epochs parameter regulates the maximum number of iterations that the training process will try to improve the accuracy of the generation model. If it detects that the model reached its top accuracy it will stop earlier. Each iteration consumes computing power and time to complete. Recommended values for this parameter are:
- Test data for the application testing purposes: 10-20
- Test data for the analytical purposes: 20-50
- Synthetic data for training other ML models: 50-100
The Null values parameter defines the action the training process will apply to the rows with the NULL values. There are two options available:
- Replace NULL values with the column average value that might affect the accuracy of the generation
- Drop the entire row, if at least one of the columns has the NULL value
It is recommended to use the replace action for the application testing, and the drop option for the analytical or data science needs.
- The Differential privacy option allows you to activate a special process during the synthetic data generation model training that mathematically guarantees the risk of disclosure of personal/sensitive data to be less or equal to a value known as privacy budget (ε). The lower the epsilon (ε) is the more privacy is added, but the lower accuracy is. The privacy budget determines how one's personal data present in the database influences the generated table or a risk for a person to reveal her personal data. It is recommended to use values 0-3 – for high, 3-15 – for medium, and 15+ – for low privacy.
Differential privacy
Differential privacy (DP) is a mechanism to ensure mathematically guaranteed privacy of data. That means that an intruder cannot identify whether a certain piece of information was presented in a trained data using limited queries to the generated data. Therefore, with differential privacy applied to sensitive data, the goal is to give each individual roughly the same privacy that would result from having their data removed.
From the technical point of view, DP is implemented by adding a Laplace noise to the stochastic gradient descent algorithm results. This allows the neural network to learn more global patterns, that are not affected much by individual records. Thus, Information about individuals is removed from the model, leading to satisfactory results in terms of DP.
Unfortunately, such manipulations with optimization algorithms lead to some drawbacks, the most significant of which include:
- Accuracy degradation
- Training time increasing
Since the DP mechanism is disrupting in its nature, the learning step should be kept small to ensure convergence. What is more, according to Frisk et al [1], "to obtain the best possible epsilon, gradients need to be perturbed on a single sample basis, i.e. training the deep neural network with a batch size of 1. This dramatically increases the training time by orders of magnitude, from minutes or seconds to train a non-private model with a larger batch size to hours and days for a private variant of the same model. It also eliminates the use of GPUs in training, since they offer no direct benefit over CPUs when training with such a small batch size".
We use the default implementation of DP optimizers from TensorFlow. The tunable hyperparameters of a DP optimizer include:
Number of micro-batches
- The number of partitions, that divide the minibatch used for training. Gradients are averaged over a micro-batch. This is what [1] is talking about.
Clipping (L2-norm)
- To ensure DP the sensitivity of each gradient needs to be bounded. In other words, we need to limit how much each individual training point sampled in a minibatch can influence gradient computations, and the resulting updates applied to model parameters. This can be done by clipping each gradient computed on each training point. The clipping is represented as a share ranging from 0 to 1 and reflects a multiplier for every single gradient.
Noise multiplier
- Noise multiplier controls the amount of noise added.
Learning rate
- Learning rate is inherited from the model and has the same meaning as for a traditional optimizer. Should be kept low for convergence.
Some dependencies between the hyperparameter's accuracy and learning rate are obtained and shown lower.
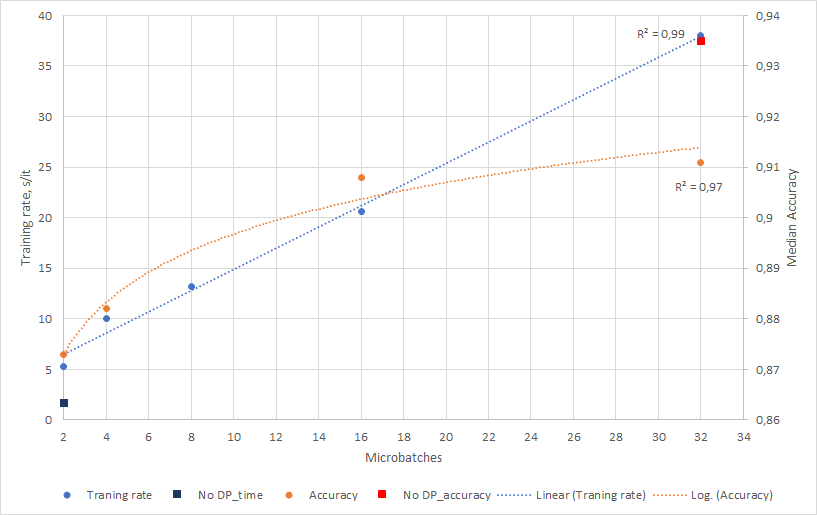
The accuracy for 8 micro-batches surprisingly was 0.83 so considered an outlier and not shown in the figure. The dependency for accuracy is fitted with log trend, dependency for training rate - with a linear trend.