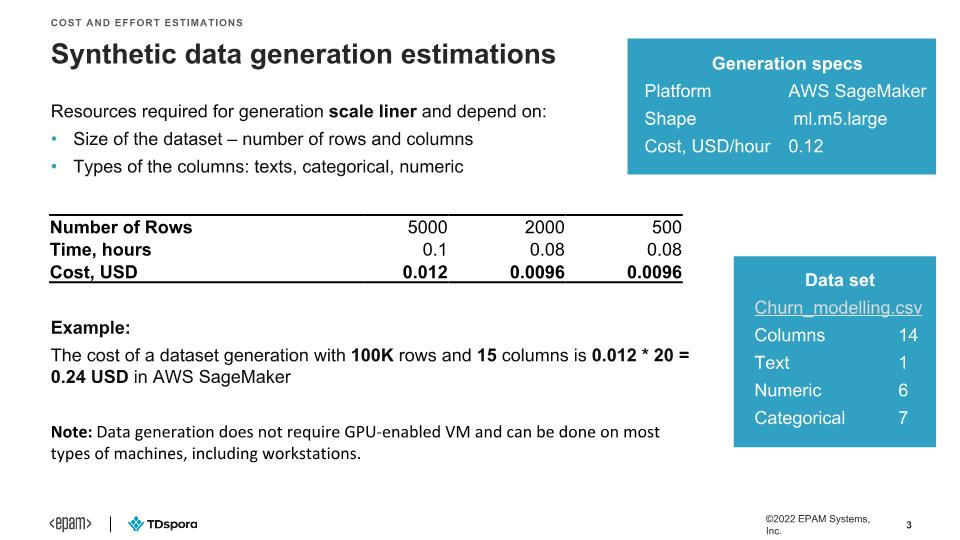
FAQ - Data generation
Do we spend privacy budget when generating data?
No, once the model is trained we do not reference the original data anymore hence do not spend the privacy budget.
How can we extract representative samples of the data to feed to the model?
If we have no access to the production data, how we can tell what is the representative sample?
A (draft):
- Random or stratified sampling will give you a representative dataset with normal distribution of data points.
- Data profiling can give you a sense of what data patterns exist. Extract sample and compare profiling results on the full data set.
- Shooting in the dark: extract the last few days or months, take one or more random business entities and extract all related data.
- Have a DP process on top of the whole dataset to run a limited number of exploratory queries.
- Give access to the data for one Data Scientist to do the investigations.
- Use cleanrooms like Databricks Cleanroom
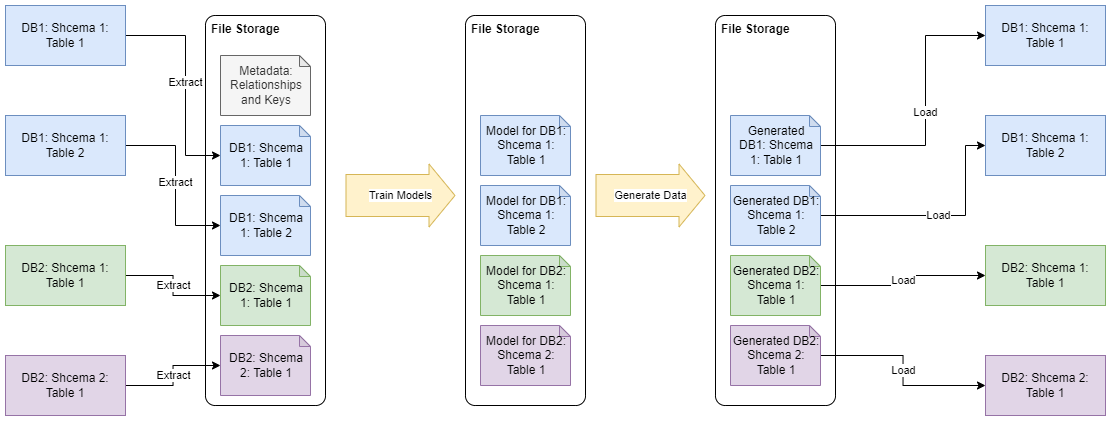
How does TDSpora handle dependencies across multiple databases?
SynGen handles each table independently. Global metadata file contains definitions of the keys and training parameters for each table. Once training of all the models completed, the generated data can be loaded into target databases using existing ETL(ELT) pipelines.
How do you generate addresses?
Q: I’m also curious about how you deal with data that might help identify people, but whose semantics might also be important to the overall synthetic data. For example, postal code – if you want to do testing that involves filling out forms, a postal code needs to be valid. If you’re introducing noise into postal codes, does that mean you move a person to a random postal code in the same country? Do you have a database of legitimate postal codes that you draw from?
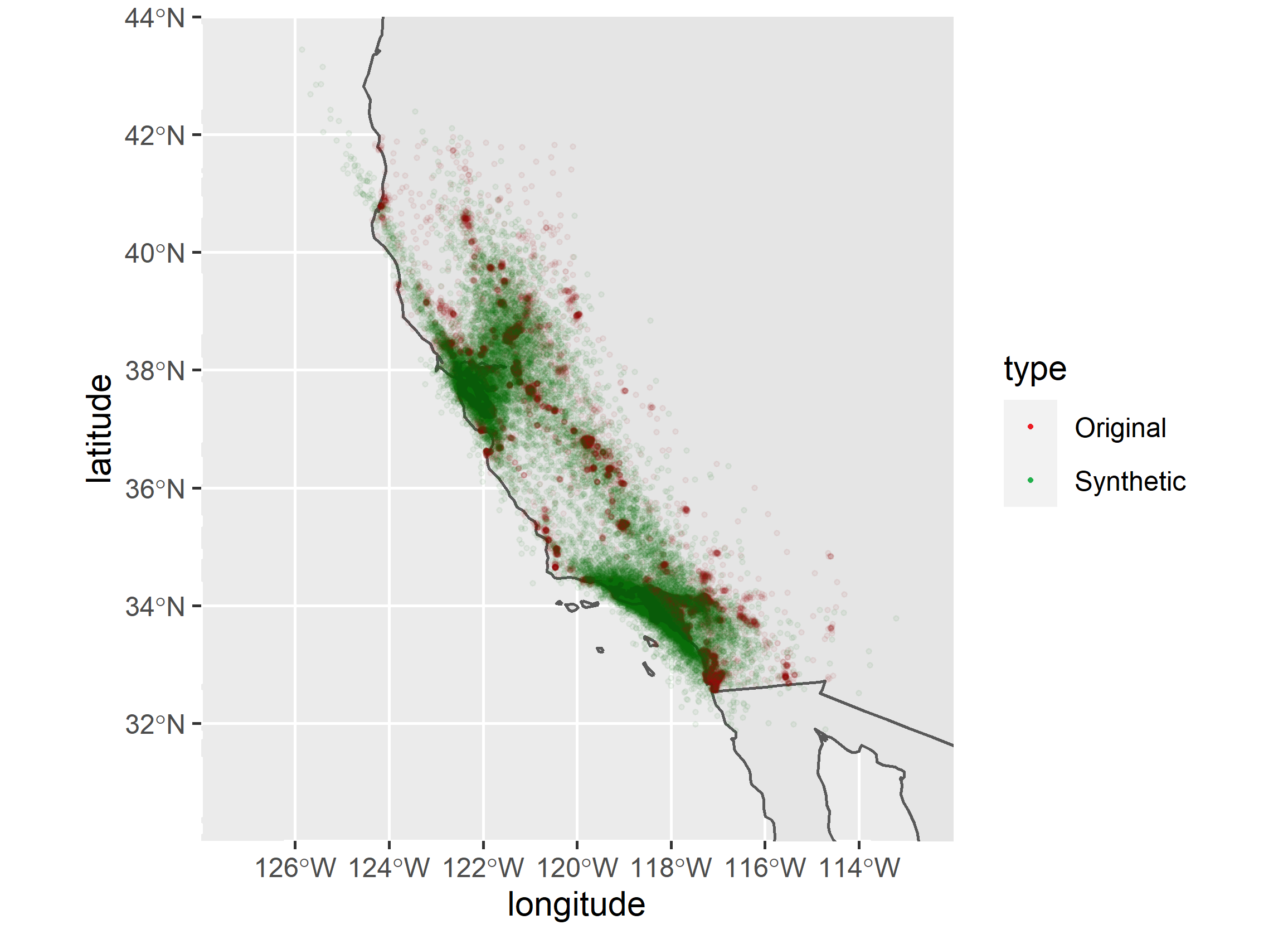
A: We have no databases with postal codes or physical addresses to draw from. However, if you have enough data in the sample, the model will learn the patterns and move people into a slightly different area thanks to the way the codes are formed. A bit different story with physical addresses. The algorithm cannot replicate them at all. In order to work it around, you can replace address lines with geo-coordinates before feeding data to the model.
Here is an example of overlay of original and generated geographic coordinates:
How do you handle data generation errors?
We do not handle the errors due to unsupervised nature of the generation model.
We recommend to use existing data quality rules (Great Expectations, deequ, dbt tests) to filter out the invalid rows. Please be aware that the distributions quality might be affected if the generated dataset is small.
Useful link: https://towardsdatascience.com/how-to-validate-the-quality-of-your-synthetic-data-34503eba6da
How do you preserve relationships between tables?
Preserving relationships between two or more tables is essential for synthetic data generation. Here is a typical wish list for relationship integrity in multi-table data:
- Referential integrity is respected, meaning that all children have parents
- It is desirable to have a small percentage of "broken" links to increase coverage during software testing
- The ability to rebalance children and parents
- Having logical correlations between children and parents be as accurate as possible.
Different priorities in this list require different generation approaches. The simplest and most popular one is the adaptation of the Kernel Density Estimator (KDE). It estimates the distribution of keys and fills in the gaps and extrapolates values beyond the boundaries of the sample data set.
The KDE generates predictable, accurate relationships always connecting parent and child, which is more suitable for the software testing scenario. However, the method is blind to the semantic correlations. For example, a patient in Nebraska can be assigned to a hospital in New Jersey.
Another, ML approach, involves generating a parent table first. The model for a child table is then trained using the original child table and low-dimensional (latent) representation of the parent table. After the synthetic child table is generated, each child row is matched (also in the latent space) with the nearest, most similar, parent row, and its foreign key. By this, we preserve not only statistical properties but the “meaning” of the relationship between parent and child tables.
For example, the figure below depicts two related tables connected by cust_id. If we would like to maintain the logical relationship between a customer's physical features and a purchased product, it is important to consider all attributes of the customer and select the largest similarity value between its latent space and three rows in the Customer table, which suggests that the row is related to the 1st parent row, and, therefore, its cust_id is assigned to 1.

Unfortunately, the accuracy of the generated links is not perfect, which can be good or bad depending on the task at hand. Synthetic data generated using this approach is demanded in software testing, data science, and business intelligence applications.
If I have a strict business rule that allows only particular combinations of values in separate columns, can it be enforced?
Currently, the rules will be followed in 80-90% of cases. You can configure data filtering rules to remove such records as the solution can generate unlimited amount of data.
Is it suitable for generating data precicely folowing the business rules?
For example, we can have a data mart with calculated columns aggregated from various sources.
Currently, we have no capabilities to define the generation rules for particular columns. At the same time, the trained model can generate highly accurate, but still approximate values with a high error accumulation rate. To avoid this issue we recommend feeding upstream data to the model and downstream it thru the transformation logic to get valuable results.
Alternatively, data validation rules can be defined or reused to filter out invalid rows. However, such an approach might affect distributions and correlations within the data set and create bias. So, it is not recommended for the AI/ML apprications.
What is the cost associated with training of a data generation model?
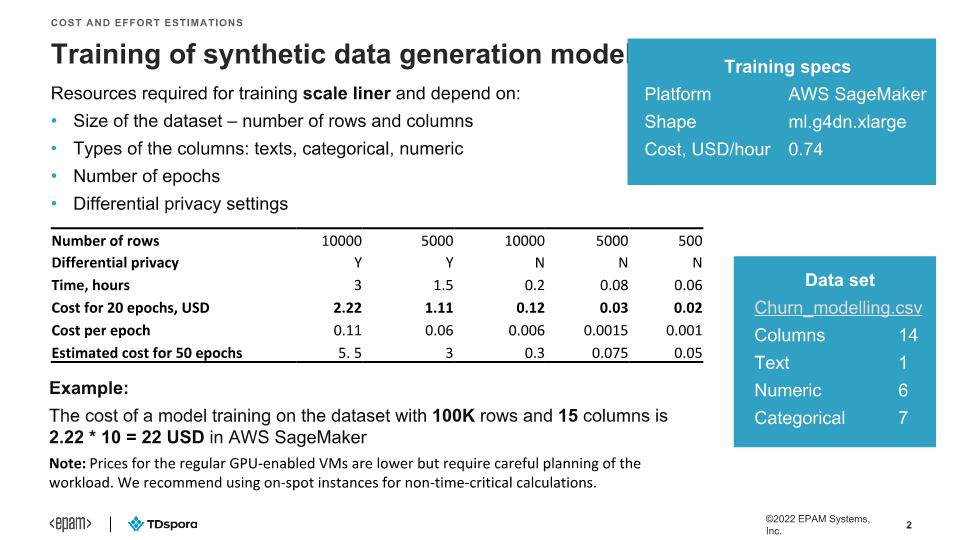
What is the data generation performance?